Linux编译工具链
1.1 Vim编辑器¶
Vim是从Vi发展出来的编辑器,具有代码补全、查找、快速跳转等功能。其中Vim共分为普通模式、输入模式、命令行模式,切换模式命令如下图。
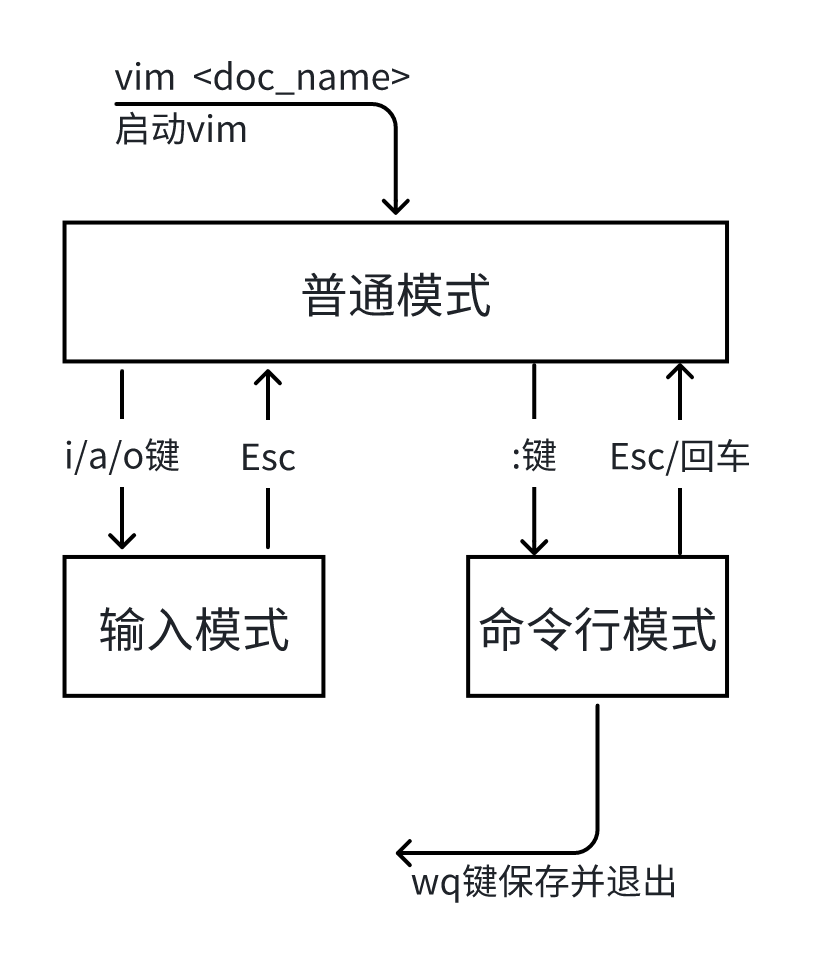
1.1.1 普通模式¶
使用vim <doc_name>命令启动Vim后,默认进入普通模式。此模式下,不能直接输入文本内容,主要进行 文本替换 、 文本查找 、 删除文字 、 复制粘贴 等操作。
- 【切换模式】
i:在光标当前位置输入。a:在光标后一个位置输入。o:在光标所在行的下一行输入。::进入命令行模式。
进入命令行模式直接跟具体命令。
- 【光标移动】
h:光标向左移动一个字符。j:光标向下移动一行。k:光标向上移动一行。l:光标向右移动一个字符。
实际上这四个键并不好用,我们可以使用上下左右四个键更直观一些。
- 【翻页】
Ctrl + f:向下翻页。Ctrl + b:向上翻页。
翻页多用于浏览文本。
- 【删除】
x:删除光标所在位置的字符。dd:删除光标所在的整行内容。dw:删除从光标位置开始到单词末尾的字符。
键盘的Delete键与x键功能一致。
- 【撤销】
u:撤销上一次的操作。Ctrl + r:重做上一次撤销的操作。
- 【复制粘贴】
yy:复制当前行。dd:剪切当前行。p(小写):粘贴内容到光标的下方。P(大写):粘贴内容到光标的上方。
在
yy前加上数字,可以复制多行,如3yy复制光标所在行开始的 3 行内容。dd既是删除,也可以实现剪切。
- 【查找】
/:查找字符串。n(小写):继续查找下一个匹配项。N(大写):继续查找上一个匹配项。
注意区分大小写,替换在命令行模式进行。
1.1.2 输入模式¶
在普通模式下,按下i/a/o键进入输入模式。此模式下,可以直接 编辑文本内容 ,按下Esc键就能回到普通模式。
该模式无特殊命令,主要进行文本修改。
1.1.3 命令行模式¶
在普通模式下,按下:键进入命令行模式。此模式下,可以执行保存内容、退出Vim等操作,按下Esc键就能回到普通模式。
- 【保存与退出】
:w:保存文件。:q:退出Vim。:q!:强制退出 Vim,即使文件修改没有保存也会退出(慎用)。:wq:保存文件,然后退出Vim。
- 【替换】
:s/旧字符串/新字符串/g:可以在当前行替换所有的旧字符串为新字符串。:%s/旧字符串/新字符串/g:整个文件范围内替换。
- 【行号】
:set nu:显示行号。:set nu!:取消显示行号。
:是从普通模式进入命令行模式,后面直接跟命令,因此替换均是在命令行模式下进行的。
1.1.4 Vim配置¶
打开Vim配置文件
在文件末尾添加下列配置,可以永久修改Tab键缩进长度、显示行号,其他需要的配置可以自行添加。
1.1.5 Vim使用练习¶
新建文件夹和 C 文件:
# 新建文件夹
mkdir c_proficient_road
cd c_proficient_road
# 新建C文件
touch vim_cmd.c
# 打开C文件
vim vim_cmd.c
使用 Vim 命令写一个基础程序,并保存,如下图。

1.2 GCC¶
GCC(GNU Compiler Collection)是 GNU 开源项目的一套开源编译器工具集,最初仅编译 C 语言,但现在的 GCC 支持编译 C++ 、Java、GO等多种编程语言,Linux内核就是采用 GCC 搭建的编译构建系统。
gcc (GUN C Compiler)是GCC中的 c 编译器,而 g++ (GUN C++ Compiler)是 GCC 中的 c++ 编译器。
gcc 和 g++ 两者都可以编译 c 和 cpp 文件,但存在差异。gcc 在编译 cpp 时语法按照 c 来编译但默认不能链接到 c++ 的库( gcc 默认链接 c 库, g++ 默认链接 c++ 库)。g++ 编译 .c 和 .cpp 文件都统一按 cpp 的语法规则来编译。所以一般编译 c 用 gcc ,编译 c++ 用 g++ 。
1.2.1 GCC安装¶
GCC 是 Linux 默认的 C/C++ 编译器,大部分 Linux 发行版都默认安装。若是需要手动安装,在终端执行以下命令安装:
# 更新软件包列表
sudo apt update
# 安装 GCC 及基础开发工具(包括 make、g++、libc-dev 等)
sudo apt install build-essential
验证 gcc 和 g++ 是否安装成功:
单独安装特定的 GCC 组件,如 g++、cmake等。
1.2.2 gcc编译器¶
gcc (GUN C Compiler)是 GCC 中的 c 编译器。
gcc 常用参数如下表:
- 【编译】
-E:仅执行预处理(生成后缀为.i的预处理文件)-S:执行预处理和编译(生成后缀为.s的汇编文件)-c:执行预处理、编译和汇编(生成后缀为.o的二进制文件)-o:链接库文件,生成可执行文件-g:嵌入调试信息,方便gdb调试-v:查看gcc编译器的版本,显示gcc执行时的详细过程
- 【代码优化】
-O0:禁用所有优化,保留完整调试信息-O1:平衡代码大小和执行速度-O2:提升执行速度,适度增加代码体积-O3:极致性能,显著增加代码体积-Os:最小化代码体积-Ofast:极致性能,忽略严格标准合规性-finline-functions:将小函数直接嵌入调用处,减少函数调用开销-funroll-loops:循环展开,减少循环控制开销,提升指令级并行性
- 【警告控制】
-Wall:打开编译告警-Werror:将所有的警告当成错误进行处理,在所有产生警告的地方停止编译
- 【库文件链接】
-static:链接静态库-share:链接动态库-l:指定要链接的 库文件名称
-l参数紧接着就是库名(无空格),例如:数学库为libm.so,参数就是-lm,即去掉lib和.so。放在/lib、/usr/lib和/usr/local/lib里的库直接用 -l 参数就能链接,其他位置的库文件需要指定目录路径。
- -L:指定要链接的 库文件路径
-L参数紧接着就是目录(无空格),除/lib、/usr/lib和/usr/local/lib以外,其他目录的库,需要使用-L参数指定目录路径,-L.即当前目录。
- -I:指定 头文件目录
-I参数紧接着就是目录(无空格),/usr/include目录一般是不用指定,其他目录则需要指定,可以用相对路径。
基础编译
编译命令格式:
# <input_name>是要编译的C文件名称
# <output_name>是生成的可执行文件的名称(默认名称为a.out/a.exe)
gcc <input_name> -o <output_name>
编译命令示例:
运行可执行文件:

1.2.3 gdb调试器¶
GDB(GNU Project Debugger)是 GNU 项目开发的开源调试工具,支持 C/C++ 、 Fortran 、 Go 等多种编程语言,主要用于检查程序运行状态、定位崩溃原因及分析逻辑错误。其核心功能包括:
- Start your program, specifying anything that might affect its behavior.(指定一些参数)
- Make your program stop on specified conditions.(断点)
- Examine what has happened, when your program has stopped.(分析crash现场)
- Change things in your program, so you can experiment with correcting the effects of one bug and go on to learn about another.(直接修改程序,看结果)
常用的 gdb 命令如下表,可以使用简写。
| 命令 | 缩写 | 功能 | 示例 |
|---|---|---|---|
run |
r |
启动程序 | run |
break <行号> |
b |
设置断点 | b 20 |
next |
n |
单步执行(不进入函数) | n |
step |
s |
单步执行(进入函数) | s |
print <表达式> |
p |
打印变量值或表达式结果 | p x |
backtrace |
bt |
查看函数调用堆栈 | bt |
info locals |
显示当前函数的局部变量 | info locals |
|
info breakpoints |
i b |
列出所有断点 | i b |
delete <断点编号> |
d |
删除断点 | d 2 |
watch <变量> |
监视变量变化时暂停 | watch x |
|
quit |
q |
退出 GDB | q |
list <行号> |
展示指定行号上下各 5 行程序 | list 8 |
|
diaplay <变量> |
监控变量变化,每次停下来都显示它的值 | dispaly a |
|
undiaplay <变量> |
取消监控变量变化 | undispaly a |
|
set var <表达式> |
修改变量的值 | set var a=15 |
|
until <行号> |
⭐进行指定位置跳转,执行完区间代码 | until 10 |
|
finish |
⭐在一个函数内部,执行到当前函数返回 | finish |
|
continue |
c |
⭐继续执行到下一个断点 | c |
修改程序
在命令行模式输入命令
set nu可以显示行数。

基础调试
① 编译程序生成调试信息
使用 gdb 调试程序,需要在 gcc 编译时加上 -g 参数生成调试信息。
② 启动 gdb
以vim_cmd.c为例,启动 gdb 调试。
启动 gdb 以后,会进入 gdb 的命令行环境,使用 gdb 的命令即可进行对应的调试工作,界面如下图所示:

③ 查看程序
查看第 8 行左右的程序。

④ 断点
在第 8 行打一个断点。

⑤ 运行

⑥ 单步执行
查看第 8 行运行前后,变量a的变化:

⑦ 查看变量信息
基于变量查看信息:

基于地址查看信息:
examine命令用于检查内存地址中的内容,缩写为x,支持多种显示格式和单位大小。
| 参数 | 功能 |
|---|---|
| 数量 | 要显示的内存单元数量(默认为1)。 |
| 格式 | x(十六进制)、d(十进制)、u(无符号十进制)、t(二进制)等。 |
| 单位 | b(字节)、h(半字,2字节)、w(字,4字节)、g(双字,8字节)。 |
具体格式如下:
为了更直观的展示examine命令,修改程序,添加一个数组:

重新编译并启动调试。

基于数组可以直观看出数量、单位的含义:
- 数量:显示多少个内存单元的内容。
- 单位:单个内存单元的字节长度。

⑧ 查看寄存器
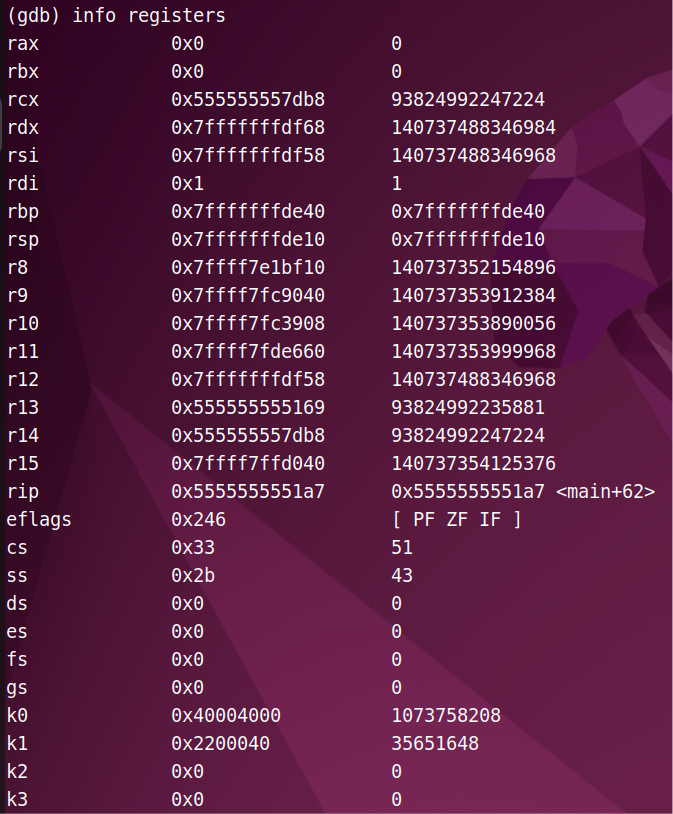
⑨ 反汇编
反汇编当前函数

Note
更多命令可以在具体使用时再细细研究。
1.3 编译过程¶
使用 gcc 对vim_cmd.c文件进行编译时,并非直接生成可执行文件,中间还经历了预处理、编译和汇编等过程,同时gcc 也提供了生成中间文件的命令,可以帮助我们更好的了解编译过程。

1.3.1 预处理¶
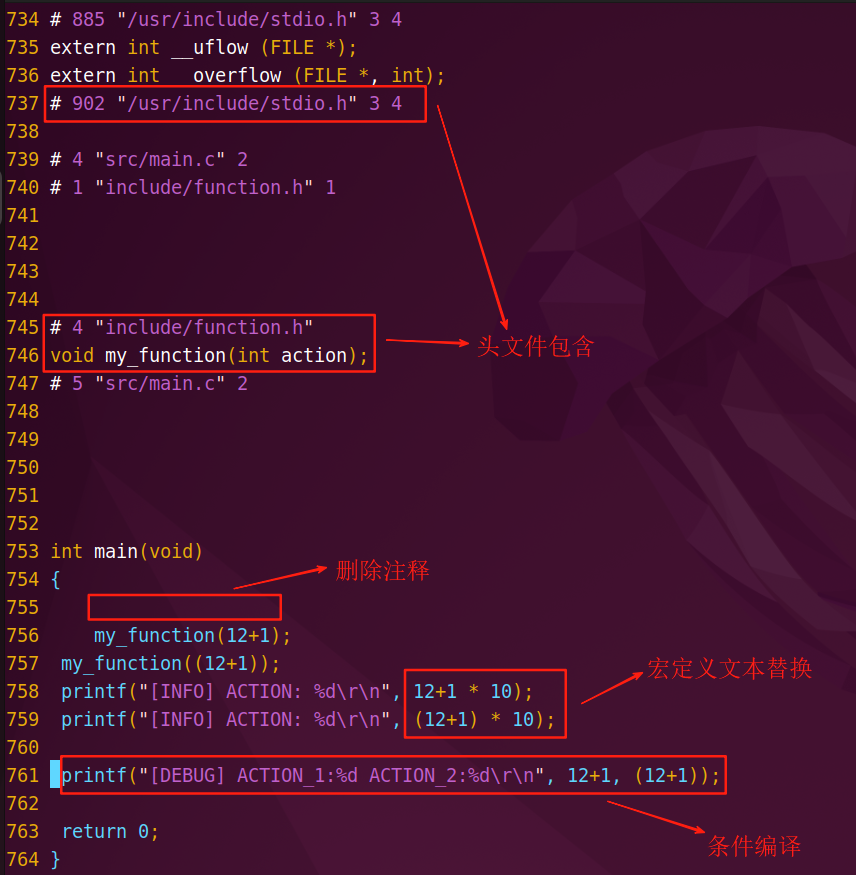
预处理过程主要进行 头文件包含 、 宏定义替换 处理,最后生成.i后缀的文件。
修改程序,添加一个宏定义并赋值给变量a,然后执行 gcc 命令生成预处理文件vim_cmd.i:
打开vim_cmd.i文件,可以看到调用的头文件被包含进来,并替换了宏常量和宏代码段。
Danger
预处理阶段不检查语法错误。

1.3.2 编译和汇编¶
编译阶段将预处理文件转化为汇编代码,生成.s后缀文件。汇编阶段将汇编代码转化为机器能执行的二进制机器码,生成.o后缀文件。
① 编译
执行如下命令,生成vim_cmd.s汇编文件,内容如下图所示。

② 汇编
执行如下命令,生成vim_cmd.o二进制文件,内容如下图所示。

1.3.3 链接¶
链接过程就是找到依赖的库文件,将目标文件链接为可执行程序。
库文件一般分静态库和动态库,静态库在编译链接时与可执行文件合为一体,动态库单独作为文件供可执行文件调用。
- 静态库 :在链接时,把库文件的代码链接到可执行文件中,更占用内存资源,但执行速度快。
- Windows系统后缀:
.lib(Library) - Linux系统后缀:
.a(Archive)
- Windows系统后缀:
- 动态库/共享库 :只有在用到的时候,才去链接库文件,可以被多个不同的程序调用,因此节省资源,但调用需要一定的装载时间。
- Windows系统后缀:
.dll(Dynamic Link Library) - Linux系统后缀:
.so(Shared Object)
- Windows系统后缀:
① 编写源码
新建文件function.c、function.h、main.c,再main.c中调用function.c的函数。

② 编译和链接
编译生成二进制文件:
链接:
编译链接一步到位:
③ 链接静态库
强制将function.c链接为静态库:
# 先将function.c编译为function.o
gcc function.c -o function.o -c
# 强制静态链接
gcc function.o main.c -o main_static -static
④ 动态链接库
强制将function.c链接为动态库:
# 生成共享库
gcc function.c -shared -fPIC -o libfunc.so
# 动态链接
gcc main.c -lfunc -L. -o main_share -Wl,-rpath='$ORIGIN'
Note
-wl用于给链接器 ld 传递参数,格式为wl,<linker-option>,-rpath='$ORIGIN'的功能是指定程序运行时搜索动态库的路径,$ORIGIN 表示可执行文件所在目录。
1.4 构建工具¶
在实际项目开发中,直接通过命令行逐一手动编译源代码文件的方式存在局限性,不仅需要记忆复杂的编译参数,更难以应对多文件协同编译、依赖关系管理和跨平台构建等工程化需求。为解决此问题,第一代 构建系统 (如Make、Ninja)应运而生,通过声明式规则文件(Makefile/build.ninja)将编译逻辑抽象为可复用的任务流。
然而随着项目的复杂度增加,手动编写和维护构建规则文件也显得效率低下。因此催生出了第二代 构建系统生成器 (如CMake、GN),通过简单的配置文件自动生成不同平台的构建文件,极大地简化了项目的编译和构建过程。
- 构建系统生成器
- Cmake:通过
CMakeLists.txt生成Makefile或build.ninja - GN:生成
Ninja构建文件,专为大型项目设计
- Cmake:通过
- 构建系统
- Make:根据
Makefile规则调用编译器(如 GCC)完成代码构建 - Ninja:替代
make,专注于快速执行构建步骤(需输入文件如build.ninja)
- Make:根据
- 编译器
- GCC:GNU 项目的一套编译工具
- Clang:LLVM 项目的编译工具

1.4.1 准备环境¶
新建文件夹2.make_cmake_gn_ninja,相关文件按如下目录移植(均是编译章节用到的源文件)。
└── 2.make_cmake_gn_ninja
├── build
├── include
│ └── function.h
├── out
└── src
├── function.c
└── main.c
1.4.2 Make¶
Make 是一个广泛使用的构建工具,与 GCC 一样来源于 GNU 项目,因此又称 GNU Make。Make 通过一个名为 makefile 的文件知道要如何编译你的项目,因此我们要在项目中编写一个 makefile 文件。
Make 的功能
- Make 允许用户在不了解具体构建细节的情况下编译和安装软件包——因为这些细节已记录在你提供的
makefile中。 - Make 能 自动确定需要更新的文件 ,若某个非源文件依赖于另一个非源文件,Make 会 自动推断正确的更新顺序 。
- 当修改部分源文件后运行 Make,它仅重新编译直接或间接依赖这些修改文件的非源文件,而非整个项目。
- Make 除构建软件包外,还可控制安装/卸载一个包。
Note
源文件指开发者直接编写和维护的文件,如.c、.py这类文件,而非源文件指的是通过工具生成的中间或最终文件,如.o、.out文件。
makefile 的规则
如下便是一个规则,而makefile就是有多个规则组成的。
# target: 目标文件
# dependencies: 依赖文件
# commands: 要执行的命令
target: dependencies ...
commands
...
makefile 简单应用
在根目录下新建makefile文件,文件名称就是makefile,无后缀。
# 定义工程目录
SRC_DIR := src
INCLUDE_DIR := include
OBJ_DIR := build
BIN_DIR := out
# 包含头文件路径,启动编译警告,生成调试信息
CFLAGS = -I$(INCLUDE_DIR) -Wall -g
# 可执行文件
TARGET = $(BIN_DIR)/main
# 获取src目录下所有.c文件列表
SOURCES = $(wildcard $(SRC_DIR)/*.c)
# 将.c路径替换为.o路径
OBJS = $(patsubst $(SRC_DIR)/%.c,$(OBJ_DIR)/%.o,$(SOURCES))
# 默认目标
all : $(TARGET)
@echo "all done"
# 编写编译规则
$(TARGET) : $(OBJS)
gcc $^ -o $@
$(OBJ_DIR)/%.o : $(SRC_DIR)/%.c
gcc $< -o $@ -c $(CFLAGS)
# 清理规则
.PHONY: clean
clean :
rm -rf $(OBJ_DIR)/*.o
根目录执行编译
运行可执行文件

可以清理build目录下的.o文件
Note
网上有很多简单的makefile示例,就是基本的根据规则赋值gcc命令,我认为不符合实际项目需求,因此做了一个较综合的makefile示例,用到了变量、通配符、函数等功能。
makefile 基础
先较系统的介绍用到的
makefile基础,然后再分析我们的makefile文件。
- 【变量】
:=:立即展开(在定义时求值)=:延迟展开(在使用时求值)?=:条件赋值(仅在未定义时赋值)
- 【自动变量】
$@:当前规则的目标文件$<:当前规则的第一个依赖文件$^:当前规则的所有依赖文件(去重)$*:通配符%匹配的部分
- 【通配符】
%:匹配任意长度的字符串,可以配合函数和模式规则使用*:
- 【函数】
$(wildcard PATTERN):获取匹配PATTERN的文件列表,PATTERN是通配符表达式$(patsubst PATTERN,REPLACEMENT,TEXT):将TEXT中匹配PATTERN的部分替换为REPLACEMENT*PATTERN: 匹配模式(必须包含%) *REPLACEMENT: 替换模式(%对应捕获的内容) *TEXT: 待处理的文本或变量$(shell COMMAND):执行 Shell 命令并返回结果
- 【条件判断】
makefile 解析
① 变量声明
按照$(<变量>)格式使用变量:
# 定义工程目录
SRC_DIR := src
INCLUDE_DIR := include
OBJ_DIR := build
BIN_DIR := out
# 包含头文件路径,启动编译警告,生成调试信息
CFLAGS = -I$(INCLUDE_DIR) -Wall -g
# 可执行文件
TARGET = $(BIN_DIR)/main
② 函数
$(wildcard PATTERN)函数获取src目录下的所以.c文件$(patsubst PATTERN,REPLACEMENT,TEXT)函数将.c路径替换为.o路径
# 获取src目录下所有.c文件列表
SOURCES = $(wildcard $(SRC_DIR)/*.c)
# 将.c路径替换为.o路径
OBJS = $(patsubst $(SRC_DIR)/%.c,$(OBJ_DIR)/%.o,$(SOURCES))
③ 默认目标
在命令前加上$,终端就不会显示输入的命令,而只显示输出结果。
④ 链接规则
$(OBJS)变量为所有.o依赖文件$(TARGET)变量为目标文件$^代指所有依赖文件,即build\main.o、build\function.o$@代指目标文件,即out\main
⑤ 模式规则
%通配符会动态生成目标和依赖关系- 当需要构建
build/main.o时,Make 检查是否存在src/main.c %捕获 main,$<展开为src/main.c,$@展开为build/main.o
- 当需要构建
- 此规则,逐个编译每个
.c文件,生成对应的.o文件
⑥ 清理规则
.PHONY: clean声明 clean 为伪目标,告诉 Make 不要检查 clean 文件是否存在,而是直接执行其命令。
Note
更多Make的使用可以在实际应用中不断学习,因为我们一般不会手写makefile,而是使用Cmake自动生成makefile。
1.4.3 Ninja¶
Ninja 是由谷歌的一名程序员推出的一款注重速度的构建工具。根据官网描述,在一个超 3000 源文件的谷歌浏览器项目中,修改完一个文件后,其他构建系统需要 10s 开始构建,而 Ninja 仅需不到 1s 。
Ninja有两个重要特点:
- 并行编译 :没有依赖的命令可以并行执行。
ninja默认使用的并行数为CPU数量,一般不用手动设置并行数,除非想限制ninja使用的CPU数量。 - 增量编译 :根据文件的时间戳进行分析,如果某个文件的时间戳发生了改变,则依赖于这个文件的命令以及其他依赖于这个命令的命令都会被重新执行,以此达到增量编译的效果。
安装 Ninja :
Ninja 基础语法
相较于 Make ,Ninja 的语法更加简单,没有复杂的条件判断和函数,都是一些直接执行的命令。
- 【变量】
- 定义常量或路径,简化重复配置
- 注意:
* <value>后面不要有多余的空格
+ 【规则】
- 定义如何从输入文件生成输出文件
- 注意:
* $in:输入文件,由 build 语句中的输入文件自动填充
* $out:输出文件,由 build 语句中的输出文件自动填充
+ 【构建目标】
- 声明文件生成规则和依赖关系
- 参数:
* <output_file>自动填充到指定规则的$out变量中
* <input_file>自动填充到指定规则的$in变量中
+ 【默认模板】
- 指定默认构建目标(类似 Makefile 的 all)
+ 【伪目标】
- 定义不生成文件的操作(如清理)
编译文件
根目录新建build.ninja文件,添加如下内容:
# 变量定义
cc = gcc
cflags = -Iinclude -Wall -g
src_dir = src
obj_dir = build
bin_dir = out
# 规则定义
## 编译
rule compile
command = $cc $in -o $out $cflags -c
description = Compile $out
## 链接
rule link
command = $cc $in -o $out
description = Link $out
# 构建目标
## 编译源文件
build $obj_dir/main.o : compile $src_dir/main.c
build $obj_dir/function.o : compile $src_dir/function.c
## 链接目标文件
build $bin_dir/main : link $obj_dir/main.o $obj_dir/function.o
# 默认目标
default $bin_dir/main
# 清理规则
build clean: phony
command = rm -rf $obj_dir/*.o $bin_dir/main
description = clean done
编译构建
清理中间文件

Note
以上介绍的是ninja的一些基础,足以编译构建简单的项目,但更多的时候我们使用Cmake或GN生成ninja文件。
1.4.4 CMake¶
CMake 是个一个开源的跨平台自动化建构系统,不依赖于某特定编译器,并可支持多层目录、多个应用程序与多个函数库。CMake 通过使用简单的配置文件 CMakeLists.txt,自动生成不同平台的构建文件(如 Makefile、Ninja 构建文件、Visual Studio 工程文件等)。
CMake 的功能与优势
- 跨平台支持 :CMake 支持多种操作系统和编译器,使得同一份构建配置可以在不同的环境中使用。
- 简化配置 :通过
CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本。 - 自动化构建 :CMake 能够自动检测系统上的库和工具,减少手动配置的工作量。
- 灵活性 :支持多种构建类型和配置(如 Debug、Release),并允许用户自定义构建选项和模块。
安装 CMake
如下所示,是一个标准的 STM32 的 CMake 配置文件,基于这个文件分析一下常用的 CMake 语法。
cmake_minimum_required(VERSION 3.22)
#
# This file is generated only once,
# and is not re-generated if converter is called multiple times.
#
# User is free to modify the file as much as necessary
#
# Setup compiler settings
set(CMAKE_C_STANDARD 11)
set(CMAKE_C_STANDARD_REQUIRED ON)
set(CMAKE_C_EXTENSIONS ON)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_C_STANDARD_REQUIRED ON)
# Define the build type
if(NOT CMAKE_BUILD_TYPE)
set(CMAKE_BUILD_TYPE "Debug")
endif()
# Set the project name
set(CMAKE_PROJECT_NAME F1ArchDesgin)
# Include toolchain file
include("cmake/gcc-arm-none-eabi.cmake")
# Enable compile command to ease indexing with e.g. clangd
set(CMAKE_EXPORT_COMPILE_COMMANDS TRUE)
# Core project settings
project(${CMAKE_PROJECT_NAME})
message("Build type: " ${CMAKE_BUILD_TYPE})
# Enable CMake support for ASM and C languages
enable_language(C ASM CXX)
# Create an executable object type
add_executable(${CMAKE_PROJECT_NAME})
# Add STM32CubeMX generated sources
add_subdirectory(cmake/stm32cubemx)
# Link directories setup
target_link_directories(${CMAKE_PROJECT_NAME} PRIVATE
# Add user defined library search paths
)
# Add sources to executable
target_sources(${CMAKE_PROJECT_NAME} PRIVATE
# Add user sources here
Abstract/gpio/led_base.cpp
Abstract/gpio/button_base.cpp
Abstract/gpio/adc_base.cpp
Abstract/communication/can_base.cpp
Abstract/communication/uart_base.cpp
Bsp/gpio/led_stm32.cpp
Bsp/gpio/button_stm32.cpp
Bsp/gpio/adc_stm32.cpp
Bsp/communication/can_stm32.cpp
Bsp/communication/uart_stm32.cpp
Bsp/display/oled.c
Services/step_motor.cpp
Services/battery_voltage.cpp
UserApp/main.cpp
)
# Add include paths
target_include_directories(${CMAKE_PROJECT_NAME} PRIVATE
# Add user defined include paths
Abstract/gpio
Abstract/communication
Bsp/gpio
Bsp/communication
Bsp/display
Services
UserApp
)
# Add project symbols (macros)
target_compile_definitions(${CMAKE_PROJECT_NAME} PRIVATE
# Add user defined symbols
)
# Add linked libraries
target_link_libraries(${CMAKE_PROJECT_NAME}
stm32cubemx
# Add user defined libraries
)
#target_link_options(${PROJECT_NAME} PRIVATE -u _printf_float)
# 生成HEX文件
add_custom_command(
TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_OBJCOPY} -O ihex $<TARGET_FILE:${PROJECT_NAME}> ${PROJECT_NAME}.hex
COMMENT "Generating HEX file: ${PROJECT_NAME}.hex"
)
【常用语法】
- 指定 CMake 的最低版本要求
- 定义项目的名称,可以同时指定编程语言支持
- 使能编程语言支持(如果
project语法没有使能可以用这个语法)
- 设置变量,变量的使用方法为
${<variable>}
- 指定要生成的可执行文件和源文件(可不指定源文件,统一使用
target_sources语法添加)
- 添加源代码到可执行文件
PUBLIC:依赖项既会作用于当前目标,也会传递给依赖它的其他目标。PRIVATE:依赖项仅作用于当前目标,不传递。INTERFACE:依赖项不作用于当前目标,但会传递给依赖它的其他目标。
- 指定头文件搜索路径
- 添加项目的宏定义
- 添加链接库的搜索路径
- 指定链接库的名称(一般是
add_library或add_executable声明的名称)
- 添加链接器的额外选项(比如添加 GCC 的编译参数)
这 4 条命令足以编译构建一些简单项目,比如我们的示例项目。
...的参数表示一个参数列表,如add_executable(<target> <source_files>...)中的源文件参数,可以是多个源文件;
[ ]的参数为可选参数,如project(<PROJECT-NAME> [<language-name>...])通常只使用必要参数<PROJECT-NAME>。不常用的可选参数将呈现,详细的参数可以看 CMake官网。
除了上面介绍的一些简单构建系统会用到的语法,还有一些复杂构建系统会用到和在现代 CMake 被取代的语法(会标注被取代的语法)。
【其他常用语法】
- 输出信息到终端
STATUS:输出为正常信息,不影响构建。WARNING:输出为黄色警告,但不终止。SEND_ERROR:阻止生成,但不停止配置。
更多
mode可以自行查找。
- 添加子目录构建,将指定目录的
CMakeLists.txt加入构建系统
- 加载并运行指定文件中的 CMake 命令
- 添加头文件搜索路径(现代 CMake 工程中多使用
target_include_directories代替)
- 创建一个库(动态或静态)
STATIC:静态库SHARED:动态库
- 寻找项目需要的包
REQUIRED:表示这个项目要这个包才能运行,必须找到它<version>:包的版本
【file 语法】
- 读取文件内容到变量
OFFSET <offset>:从文件指定偏移量开始读取LIMIT <max-in>:限制读取的最大字节数HEX:可选,将内容转换为十六进制格式
- 解析来自文件的 ASCII 字符串列表到变量
<options>常用选项如下: *LENGTH_MAXIMUM <max-len>:仅读取长度小于等于max-len的字符串 *REGEX <regex>:仅保留匹配正则表达式的字符串 *ENCODING <encoding>:指定编码格式
- 将匹配的文件列表存于变量
RELATIVE <path>:返回相对于指定路径的文件路径<globbing-expressions>:通配符表达式
更多
file语法的使用查看CMake官网
Cmake 构建 Makefile 文件
项目根目录下新建CMakeLists.txt文件,同时建议将先前使用的makefile删除或移动到其他目录,比如build目录,防止与CMake生成的Makefile冲突,当前目录内容如下:

CMakeLists.txt内容如下:
# 指定Cmake的最底版本需求要求
cmake_minimum_required(VERSION 3.22)
set(CMAKE_PROJECT_NAME main)
# 指定项目名称和变成语言
project(${CMAKE_PROJECT_NAME} C)
# 通过CMake内置宏指定C的语言标准版本使用C11
set(CMAKE_C_STANDARD 11)
# 添加可执行文件
add_executable(${CMAKE_PROJECT_NAME})
# 添加编译源文件
target_sources(${CMAKE_PROJECT_NAME} PRIVATE
src/main.c
src/function.c
)
# 添加头文件搜索目录
target_include_directories(${CMAKE_PROJECT_NAME} PRIVATE
include
)
CMake构建
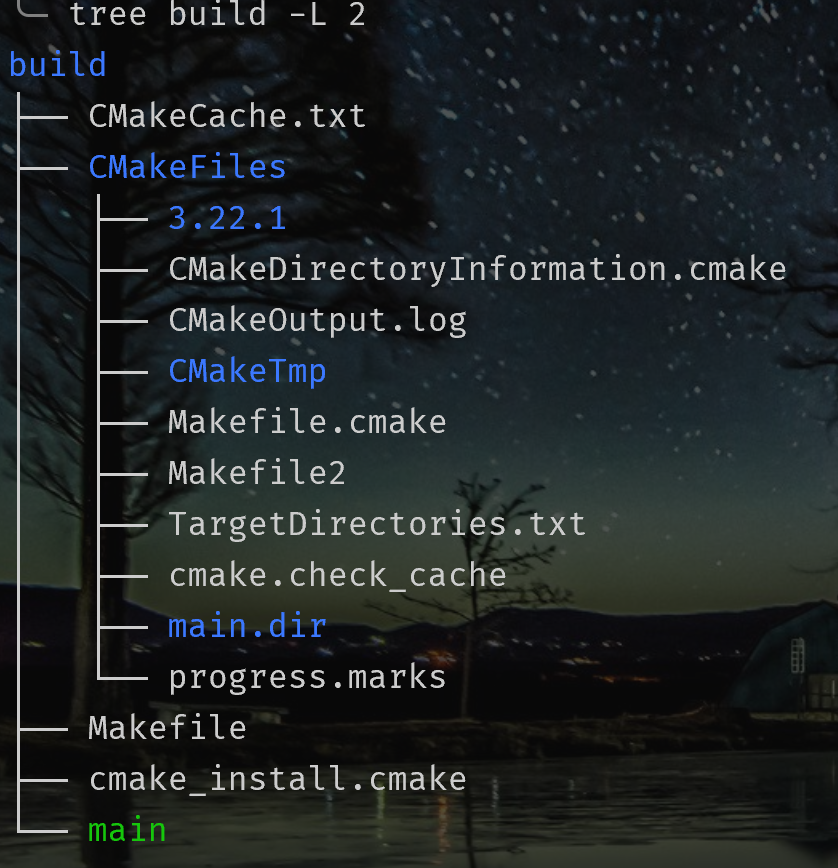
CMake构建以后,会生成一系列文件和一个CmakeFiles文件夹。其中,默认生成Makefile文件,用于使用make命令编译;若使用-G参数指定Ninja则会生成一个build.ninja文件,用于使用ninja命令编译:
可执行文件在out目录:
1.4.5 GN¶
待更新
1.5 编译实践¶
编译实践的目的:
- 熟悉编译各个阶段的工作内容。
- 了解常见的编译错误来自哪个阶段。
- 了解一些预处理工作是如何被编译器优化的。
编译各阶段的核心任务如下:
- 预处理 :主要进行 头文件包含 、 宏定义替换 、条件编译 、删除注释 等。
- 编译 :主要进行 语法检测 、代码优化 等。
- 汇编 :主要进行 汇编转二进制码 、 记录函数和变量地址 等。
- 链接 :主要进行 函数/变量的解析(是否定义) 、 将代码和数据的内存地址从“相对地址”修正为“绝对地址” 、 链接库 等。
1.5.1 预处理¶
预处理测试
测试程序如下:

结构目录如下:
使用 gcc 预编译程序:
查看预编译文件:
生成可执行文件:
运行可执行文件,输出内容如下:
[INFO] ACTION: 130
[INFO] ACTION: 130
[INFO] ACTION: 22
[INFO] ACTION: 130
[DEBUG] ACTION_1:13 ACTION_2:13
Danger
通过输出结果不难看出,宏定义仅进行文本替换,因此12+1和(12+1)会导致优先级不一致,使用宏定义时应注意。
1.5.2 编译¶
优化测试
测试程序如下:

使用 gcc 编译程序:
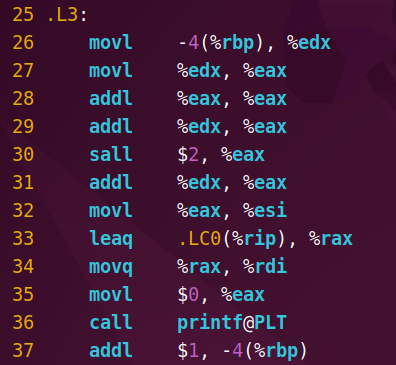
查看汇编文件,循环体内容如下:
使用 gcc 编译并优化程序:
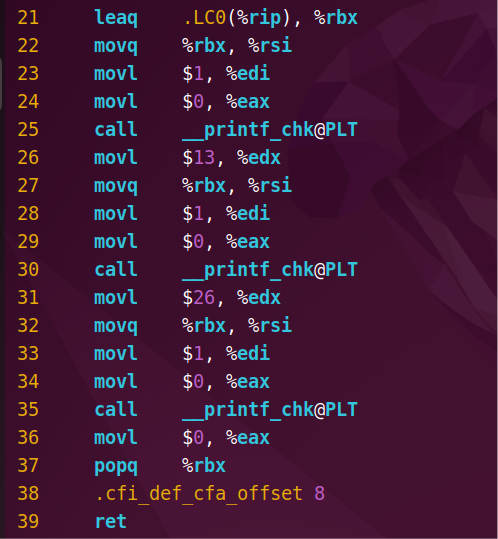
查看汇编文件,循环体展开,内容如下:
Note
若拆分阶段查看,会发现预处理阶段的文件几乎没有变化,但编译阶段的汇编文件把循环体展开了,且汇编码的量减少,实现了代码优化。
语法测试
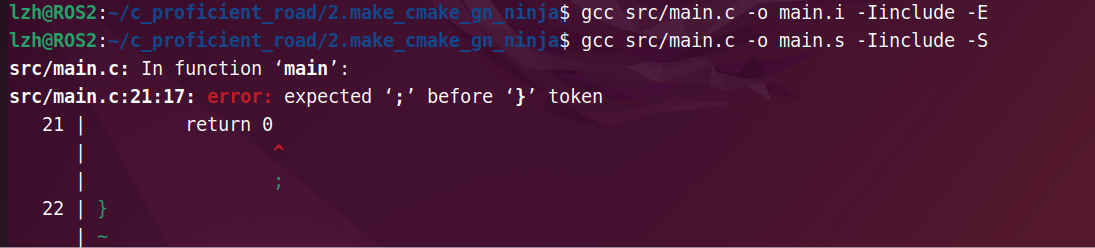
随便制造一些错误,然后分阶段测试:
① 预处理
② 编译
在编译阶段才会查出语法错误,因此预处理阶段不检查语法。
1.5.3 链接¶
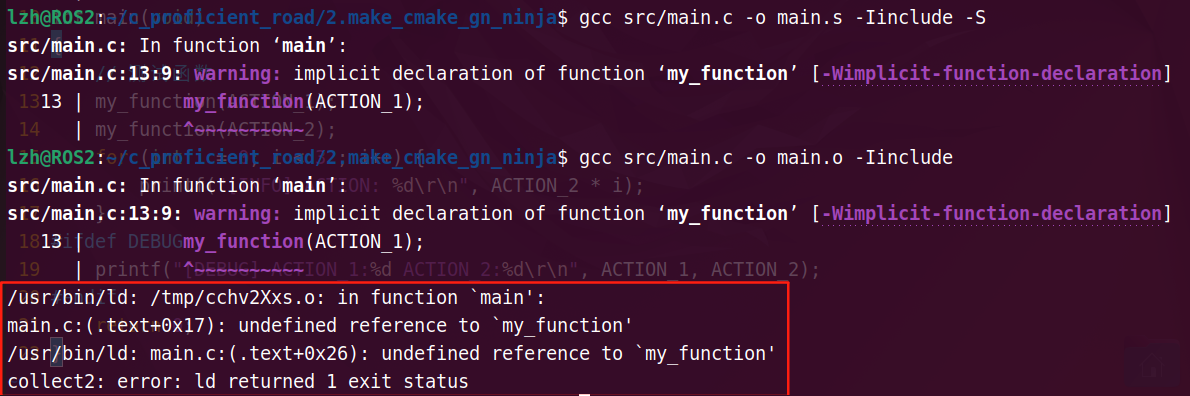
链接测试
注释头文件包含:

分别进行编译和汇编:
在编译阶段会发出一个warning,而链接则会指出问题出现在哪里。
Danger
处理函数的未定义,还有变量的未定义,均是在链接阶段检查出来的。
参考资料¶
Linux(vim)更改tab键缩进设置_linux tab 空格缩进-CSDN博客
Linux环境下GCC基本使用详解(含实例)_linux gcc-CSDN博客